The Six Cache Layers Every Developer Should Understand
By Jorge Morais · · 14 min read
Caching is not a single thing, it is a layered discipline. From in-process memory to edge CDN nodes, each layer operates on different trade-offs: speed, scope, persistence, and invalidation cost. This article maps all six layers, explains when to use each, and shows the production patterns that actually work.
Cache Performance Redis CDN Architecture
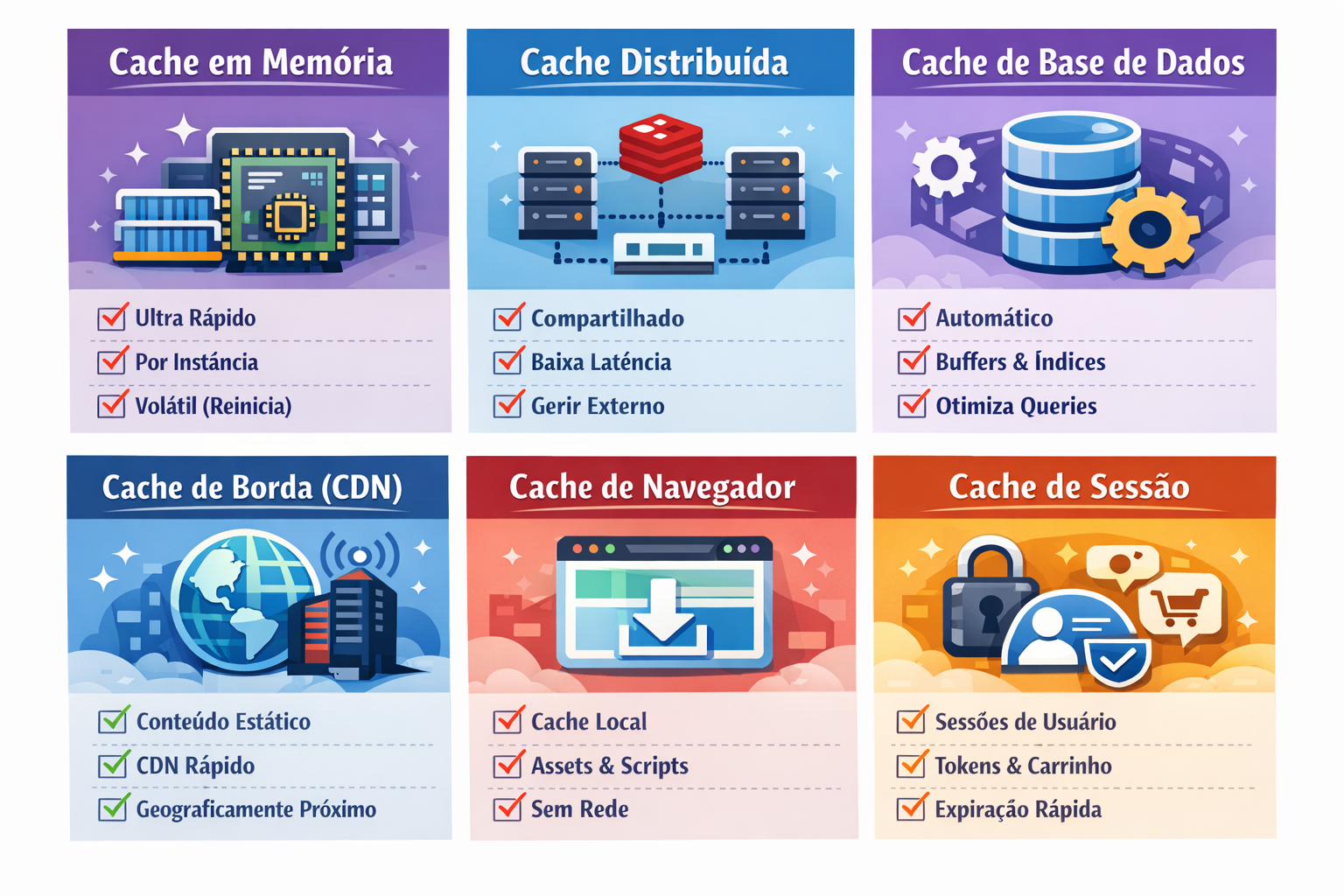
Porque Existem Camadas de Cache
Cada camada de um sistema moderno introduz latência e carga. Uma query à base de dados pode demorar 40ms. Um round-trip de rede adiciona mais 20ms. Multiplicados por milhares de utilizadores concorrentes, os números acumulam rapidamente. O cache interrompe essa cadeia, servindo respostas a partir de armazenamento rápido e local antes que o caminho lento seja sequer alcançado.
Mas não existe um cache universal. Uma estratégia que funciona brilhantemente para tokens de sessão falha para contagens de inventário em tempo real. Entender em que camada fazer cache, e porquê, é o que distingue um sistema performante de um que é apenas rápido no portátil do utilizador.
Aqui falo sobre as seis camadas, da mais rápida e local à mais lenta e distribuída.
Camada 1: Cache em Memória (In-Process)
O que é: Dados armazenados diretamente no heap de memória da aplicação, um Map simples, uma propriedade de classe, ou uma estrutura LRU proper. Sem rede, sem serialização, sem dependência externa. É o cache mais rápido que existe.
Trade-offs: Volátil (perdido ao reiniciar o processo), por instância (cada servidor tem a sua própria cópia), limitado pela RAM disponível, e requer invalidação cuidadosa para evitar dados obsoletos.
Quando usar: Configuração que raramente muda, tabelas de lookup, templates compilados, resultados de computações puras e dispendiosas, contadores de rate-limit por instância.
class LRUCache {
constructor(maxSize = 500) {
this.maxSize = maxSize;
this.cache = new Map();
}
set(key, value, ttlMs = 60_000) {
if (this.cache.has(key)) this.cache.delete(key);
if (this.cache.size >= this.maxSize) {
this.cache.delete(this.cache.keys().next().value);
}
this.cache.set(key, { value, expiresAt: Date.now() + ttlMs });
}
getValid(key) {
const entry = this.cache.get(key);
if (!entry) return null;
if (Date.now() > entry.expiresAt) { this.cache.delete(key); return null; }
// Mover para o fim = marcar como usado recentemente
this.cache.delete(key);
this.cache.set(key, entry);
return entry.value;
}
}
const configCache = new LRUCache(100);
async function getFeatureFlags(tenantId) {
const cached = configCache.getValid(`flags:${tenantId}`);
if (cached) return cached;
const flags = await db.query('SELECT * FROM feature_flags WHERE tenant_id = ?', [tenantId]);
configCache.set(`flags:${tenantId}`, flags, 5 * 60_000); // 5 minutos
return flags;
}
Camada 2: Cache Distribuída
O que é: Um store externo em memória partilhado entre todas as instâncias da aplicação. Redis e Memcached são as escolhas canónicas. Redis é mais versátil (estruturas de dados, pub/sub, opções de persistência); Memcached é mais simples e por vezes mais rápido para cargas de trabalho puras de chave-valor.
Trade-offs: Um hop de rede (tipicamente 0,5–2ms em LAN), custo de serialização, overhead operacional de gerir um serviço externo, mas estado partilhado entre todos os nós e persistência opcional.
Quando usar: Dados de sessão, resultados computados por utilizador, rate limiting partilhado, carrinhos de compras, classificações, qualquer coisa que deva ser consistente entre múltiplas instâncias de servidor.
const redis = require('ioredis');
const client = new redis({ host: 'redis-cluster', port: 6379 });
// Padrão cache-aside: leitura com TTL explícito
async function getUserProfile(userId) {
const key = `user:profile:${userId}`;
const cached = await client.get(key);
if (cached) return JSON.parse(cached);
const profile = await db.users.findById(userId);
if (!profile) return null;
await client.setex(key, 900, JSON.stringify(profile)); // 15 minutos
return profile;
}
// Invalidar na escrita — manter o cache consistente
async function updateUserProfile(userId, data) {
await db.users.update(userId, data);
await client.del(`user:profile:${userId}`); // invalidar, não atualizar
}
// Mutex para evitar "thundering herd", só uma request reconstrói o cache
async function getCachedWithLock(key, buildFn, ttlSeconds) {
const cached = await client.get(key);
if (cached) return JSON.parse(cached);
// SET NX = apenas se não existir (lock atómico)
const locked = await client.set(`lock:${key}`, '1', 'NX', 'EX', 10);
if (!locked) {
await new Promise(r => setTimeout(r, 50));
return getCachedWithLock(key, buildFn, ttlSeconds);
}
const value = await buildFn();
await client.setex(key, ttlSeconds, JSON.stringify(value));
await client.del(`lock:${key}`);
return value;
}
Camada 3: Cache de Base de Dados
O que é: Cache construído diretamente no motor de base de dados. Inclui o buffer pool (shared_buffers do PostgreSQL, buffer pool do InnoDB do MySQL), o page cache do SO, e caches de resultados de queries. A base de dados gere automaticamente o que fica em memória com base nos padrões de acesso.
Quando usar: Sempre. Esta camada está sempre ativa. O teu trabalho é configurá-la bem e escrever queries que beneficiem dela.
-- PostgreSQL: verificar a taxa de acerto do buffer pool
-- Uma taxa abaixo de 95% sugere que precisas de mais shared_buffers
SELECT
sum(heap_blks_hit) AS cache_hits,
sum(heap_blks_read) AS disk_reads,
round(
sum(heap_blks_hit)::numeric /
nullif(sum(heap_blks_hit) + sum(heap_blks_read), 0) * 100, 2
) AS hit_ratio_pct
FROM pg_statio_user_tables;
-- Índices parciais aumentam drasticamente a eficiência do cache
-- Em vez de fazer cache da tabela orders completa, apenas orders ativas
CREATE INDEX idx_orders_active ON orders (user_id, created_at)
WHERE status IN ('pending', 'processing');
-- Evita SELECT * - busca apenas o que precisas
SELECT id, total, status FROM orders WHERE user_id = $1 AND status = 'active';
Camada 4: Cache de Borda (CDN e Proxy Reverso)
O que é: Um cache que fica entre a internet e os teus servidores de origem, um CDN como Cloudflare, Fastly ou AWS CloudFront, ou um proxy reverso como Varnish ou Nginx. Pedidos de conteúdo cacheável são servidos diretamente de um nó geograficamente próximo do utilizador, sem nunca chegar ao backend.
Quando usar: Assets estáticos, respostas de API iguais para todos os utilizadores (listagens de produtos públicas, artigos de blog, páginas de preços), e qualquer conteúdo que tolere alguma desatualização.
// Express, definir headers Cache-Control para cache de borda
app.get('/api/products', async (req, res) => {
const products = await getProducts();
// Cache no CDN por 5 minutos, servir obsoleto por até 1 hora enquanto revalida
res.set('Cache-Control', 'public, max-age=300, stale-while-revalidate=3600');
res.set('Vary', 'Accept-Language'); // cache separado por idioma
res.json(products);
});
// Surrogate keys (Cloudflare / Fastly) - invalidar por tag, não por URL
app.get('/api/products/:id', async (req, res) => {
const product = await getProduct(req.params.id);
res.set('Cache-Tag', `product:${product.id} category:${product.categoryId}`);
res.set('Cache-Control', 'public, max-age=600');
res.json(product);
});
// Quando um produto muda: purgar apenas as respostas com essa tag
async function onProductUpdated(productId) {
await fetch('https://api.cloudflare.com/client/v4/zones/:zone/purge_cache', {
method: 'POST',
headers: { 'Authorization': 'Bearer ' + process.env.CF_TOKEN },
body: JSON.stringify({ tags: [`product:${productId}`] })
});
}
Camada 5: Cache de Navegador
O que é: O cache mantido pelo browser do utilizador, guardando respostas HTTP localmente para que visitas subsequentes sirvam assets do disco sem qualquer pedido de rede. Controlado inteiramente através de headers de resposta HTTP.
Quando usar: Bundles JavaScript, CSS, imagens, fontes, qualquer coisa com um hash de conteúdo no nome do ficheiro pode ser cacheada indefinidamente. Documentos HTML e respostas de API precisam de TTLs mais curtos e headers de revalidação.
// Nginx, regras de cache diferentes por tipo de conteúdo
// Assets com hash (ex: main.a3f2c8.js), cache para sempre
location ~* \.(js|css|woff2)$ {
add_header Cache-Control "public, max-age=31536000, immutable";
}
// Imagens sem hash - cache por 30 dias, revalidar com ETag
location ~* \.(png|jpg|webp|svg)$ {
add_header Cache-Control "public, max-age=2592000";
etag on;
}
// HTML — nunca cache, sempre revalidar
location ~* \.html$ {
add_header Cache-Control "no-cache";
}
// Service Worker — controlo fino de cache para SPAs
self.addEventListener('fetch', (event) => {
if (event.request.destination === 'script' ||
event.request.destination === 'style') {
event.respondWith(
caches.match(event.request).then(cached => {
return cached ?? fetch(event.request).then(response => {
const clone = response.clone();
caches.open('assets-v2').then(cache => cache.put(event.request, clone));
return response;
});
})
);
}
});
Camada 6: Cache de Sessão
O que é: Armazenamento dedicado para estado de sessão do utilizador, tokens de autenticação, preferências, conteúdo do carrinho, fluxos de trabalho em progresso. Tipicamente Redis, porque suporta expiração de chaves nativamente e consegue lidar com o padrão de leitura/escrita de acesso a sessões com alto throughput.
Quando usar: Qualquer sessão de utilizador com estado. A decisão é entre sessões com Redis (estado do lado do servidor) e JWT (estado do lado do cliente), ambos são válidos; a escolha certa depende dos teus requisitos de revogação e escalabilidade.
// Sessões Redis com express-session
const session = require('express-session');
const RedisStore = require('connect-redis').default;
app.use(session({
store: new RedisStore({ client: redisClient }),
secret: process.env.SESSION_SECRET,
resave: false,
saveUninitialized: false,
cookie: {
secure: process.env.NODE_ENV === 'production',
httpOnly: true, // não acessível a partir de JavaScript
sameSite: 'lax', // proteção CSRF
maxAge: 7 * 24 * 60 * 60 * 1000 // 7 dias
}
}));
// Revogar uma sessão específica
async function revokeSession(sessionId) {
await redisClient.del(`sess:${sessionId}`);
}
// JWT - alternativa stateless (access token curto + refresh token longo)
function issueToken(userId, roles) {
return jwt.sign(
{ sub: userId, roles },
process.env.JWT_SECRET,
{ expiresIn: '15m', algorithm: 'HS256' }
);
}
async function refreshAccessToken(refreshToken) {
const stored = await redisClient.get(`refresh:${refreshToken}`);
if (!stored) throw new Error('Token revogado ou expirado');
const { userId, roles } = JSON.parse(stored);
return issueToken(userId, roles);
}
Mapa de Decisão de Cache
| Camada | Latência | Âmbito | Sobrevive ao Restart? | Melhor Para |
|---|---|---|---|---|
| In-process | < 0,1ms | Por instância | Não | Config, lookup tables, computações quentes |
| Distribuída | 0,5–2ms | Todas as instâncias | Opcional | Estado partilhado, dados de utilizador, rate limits |
| Base de dados | Automática | Motor DB | Sim | Linhas quentes, páginas de índice, query plans |
| Borda / CDN | < 20ms | PoPs globais | Sim | Respostas públicas de API, conteúdo estático |
| Navegador | 0ms (disco) | Por utilizador | Sim | Assets, SPAs, recursos imutáveis |
| Sessão | 0,5–2ms | Por utilizador | Opcional | Estado de auth, contexto do utilizador, carrinho |
A Regra Universal
A famosa citação de Phil Karlton, "Só existem duas coisas difíceis em Ciências da Computação: invalidação de cache e escolher nomes", mantém-se precisa décadas depois. Cada estratégia de cache é apenas tão boa quanto a sua estratégia de invalidação.
Antes de adicionar qualquer cache, responde a três perguntas: quando é que estes dados mudam? (o teu TTL), quem os muda? (o teu trigger de invalidação), e qual é o custo de servir dados obsoletos? (a tua tolerância ao risco). Se não consegues responder às três, ainda não estás pronto para fazer cache desses dados.